Firstly, would the code be run and debug by any python IDEs (like Jupiter, VSCode, which I used)? if not, How can I set up the project and run?
I am working on small tool for Revit, where I need to read data from CDB and do some manipulations. I did develop a Dynamo script for my task using Excel (output from sofistik), Now planning to read directly from CDB instead of relying on Excel.
So your help would be much appreciated
@sfr and @MoShMet , I have read your replies and posts, So I felt like tagging you can help me get answer
missing CNODE and cnode objects can be found in c:/Program Files/SOFiSTiK/2022/SOFiSTiK 2022/interfaces/examples/python/sofistik_daten.py (or similar). there is class CNODE and it instance cnode. the describtion can be found in c:/Program Files/SOFiSTiK/2022/SOFiSTiK 2022/cdbase.chm chapter SOFiSTiK Data -> (20-29) Nodes -> (20) Nodes -> @Rec: 020/00.
IDE: You can use whichever IDE you want.
However you need access to the necessary files in the sofistik installation folder, so an online Jupyter notebook might require some extra work (drag and dropping files into it)
You need all the libraries and structures in order to read from the cdb, that means your script needs access to:
-The sofistik folder (for sof_cdb_w-xx.dll - library for sofistik functions)
-The sofistik_daten file (for the necessary data structures as @asiloisad mentioned)
Although, I have one more question.!
i.e how can I use for loop here instead of while? How can I find what is the range/iterating value?
Also, what is the ‘1’ ( * pos - position of the current item, starting with ‘’0’’)?
It is a little unclear, how to know the position of an object or what its position means.
Somebody could explain in layman’s terms.
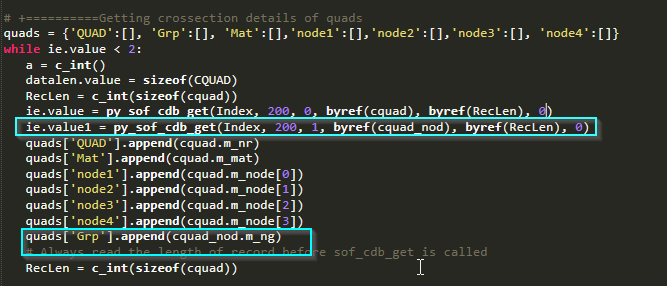
And, can someone explain to me how to include two functions together in one loop? instead of writing one more while/for loop for just one column of data. code should look like the below image, is it possible?
Select a record (e.g. 200/00 for information about quad elements)
Read the entire record line-by-line (like a text document)
To your questions:
pos:
Check out the subroutine cdb_get():
1 → Read the next line (e.g. next node)
0 → Read the first line (e.g. first node in DBinfo)
-x → Go backwards (if you’ve been reading for a while)
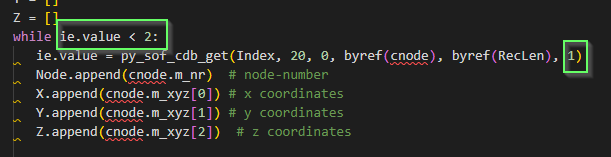
while ie.value < 2:
Also subroutine cdb_get():
0 or 1 → records exist
2 or 3 → records doesn’t exist or you’ve reached the end
Basically you’re reading each node in the cdb (first time pos 1 and 0 are equivalent) until you return value (ie.value) states that you reached the end.
Two functions at the same time:
You don’t want to do that even if you could.
Function 1: reading record 200/0
Function 2: reading record 200/1
→ You are basically jumping back and forth between the records (like reading to text documents simultaneously)
Read the cdb one record at a time line-by-line. This is the natural approach.
BTW the pos 0 at the end of your cdb_get commands will make you read the first quad element over and over again (endless loop).
Still few things are unclear to me, I am creating another thread for kwh/kwl explanation. Probably it will help me and other new developers to understand the python interface.
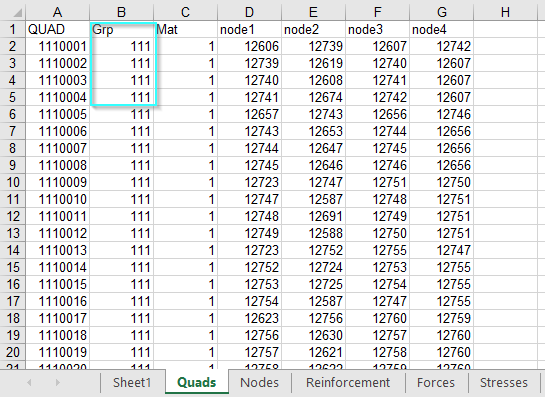
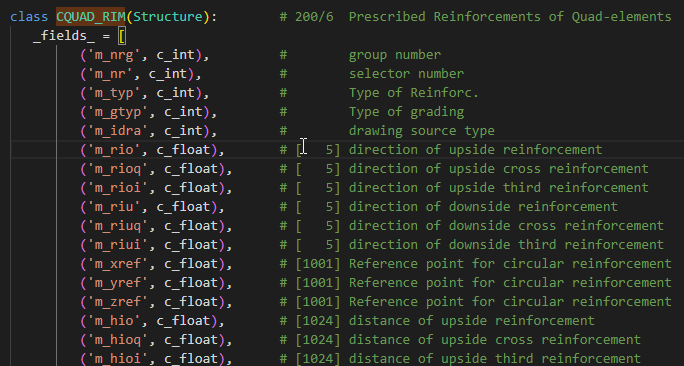
However, I have to read reinforcement details for quad elements too. I noticed that class CQUAD_RIM has no field for QUAD number!!
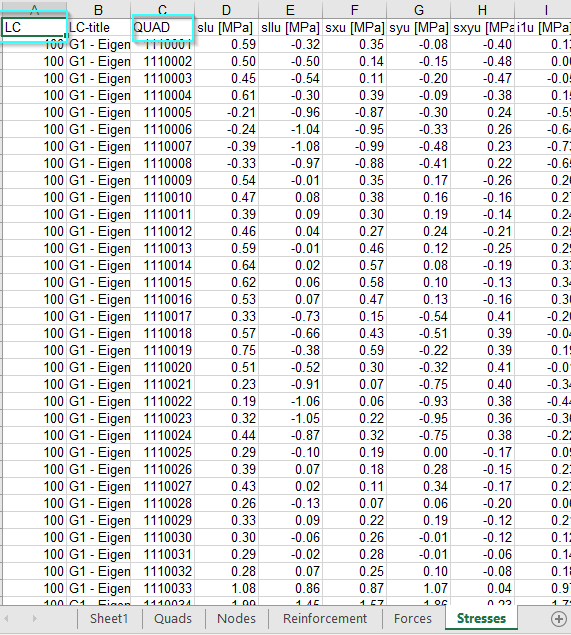
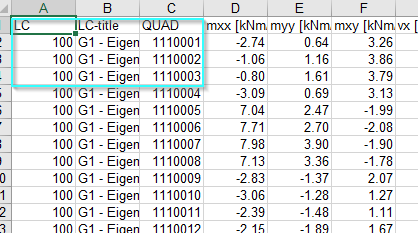
My task is, I need to extract various results of the quad elements such as forces, reinforcement, stresses etc. I want to include quad number column in all the results. How can I get include quad numbers, Grp numbers, LC etc. in all my results. Is there any Join or Union function available for this like SQL join tables?
Cross check with what is actually in your cdb! (db info)
Groups:
Has information about ALL groups (beams,springs,quads,etc).
You have to filter out the lines that you re interested in.
E.g. only Type 200 for quads.
Reinforcement details (200/6):
This is the prescribed reinforcement property, i.e. the “calculation settings” applied per quad group
E.g. concrete cover, bar diameter, max crack width
You are looking for the results → 260/DC
If you want automated join/union functions → use the result viewer and export to excel
If you are using the cdb interface
→ it is low level access (like reading a text file line by line)
You read whatever you want in the cdb, but filtering/joining/etc is up to you.
Reading the manual is proving to be a little challenging, to my knowledge.
That’s quite informative and useful.
Could also please help me with some sample python code for how explicitly filter groups for only quads(200). like SQL E.g. select grp from cgrp where type =200. Where and how can I enter the filtering value?
I know this is much to ask , but that can help me to understand and develop new code for my use cases.
In fact, I exported results into Excel from the results viewer. I have to use the results in Dynamo, so reading Excel for small data sets is easy. Nevertheless, when the use cases increase, it takes a long time to read Excel for large datasets. In order to speed up the reading process, I chose to read directly from the database.
In your perspective low level means there is no way to join the functions to get combined output?
such as, there is no referencing between two functions/classes (like foreign key between two tables)
what I’m expecting from the cdb is eg. select quad, grp from cquad join cgrp on quadnr=quadnr
Store them in the appropriate containers (e.g. lists, dictionaries, sets, numpy matrices,…)
Combine/filter the containers after.
Regard the cdb as a set of text files, that you read line-by-line.
That’s the interface in a nutshell.
E.g. finding the groups with quad elements:
ie = c_int(0)
while ie.value < 2:
datalen.value = sizeof(CGRP)
RecLen = c_int(sizeof(cgrp))
ie.value = py_sof_cdb_get(Index, 11, 0, byref(cgrp), byref(RecLen), 1)
if cgrp.m_typ == 200: # This makes sure you only store the groups with quad elements
quads['Grp'].append(cgrp.m_ng)
Basically reading everything and storing what you need
 : I am new to SOFiSTik, and advace python development.
: I am new to SOFiSTik, and advace python development.