Hello everyone,
I need to filter a few nodes (roof elements) from a structure. I filtered them using SSD and found that all the roof elements are in ´group 100 and 200´. Therefore, I attempted to retrieve all those nodes from the CDB.
To achieve this,
-
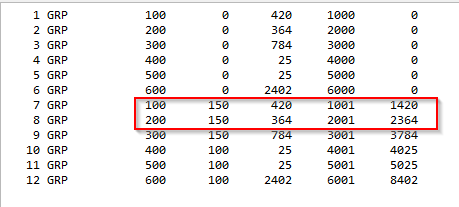
I first obtained the group numbers and their corresponding maximum and minimum values from the CDB.
-
Then I tried to filter just these nodes out of all the nodes based on this available Max, Min information.
Unfortunately, there is a discrepency with the nodes.
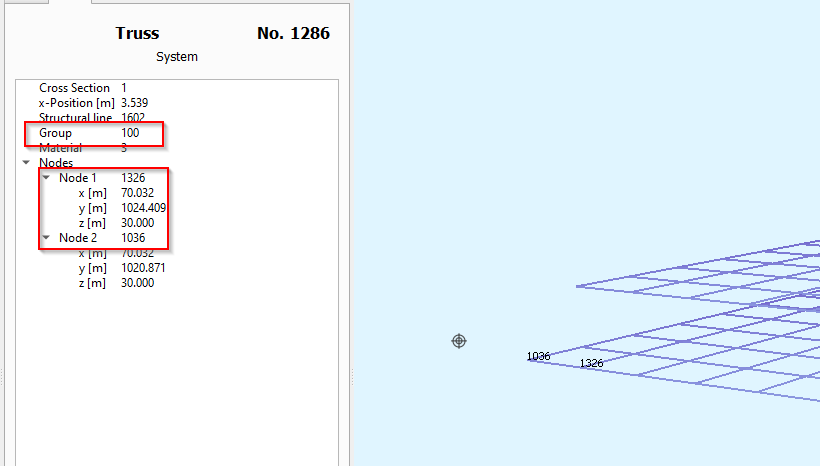
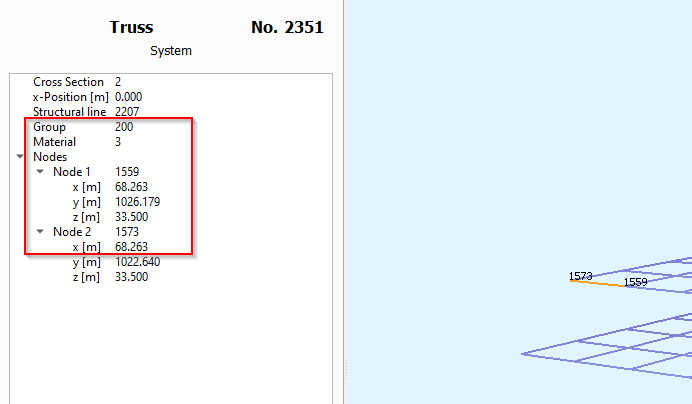
As you can see in the images below, Group 100 has a range from 1001 to a maximum of 1420, and Group 200 has from 2001 to 2364. However, from the SSD, nodes of Group 200 have numbers in other series (eg:1559, 1573), instead of starting from 2001.
Could someone assist me in extracting nodes based on groups from the CDB? Alternatively, if you could guide me in directly obtaining these roof elements (trusses), I would greatly appreciate it. Once I have access to the roof elements, my next step involves applying wind loads to these nodes.
ie = c_int(0)
groups = {'Grp':[], 'Max':[], 'Min':[]}
while ie.value < 2:
datalen.value = sizeof(CGRP)
RecLen = c_int(sizeof(cgrp))
ie.value = py_sof_cdb_get(Index, 11, 0, byref(cgrp), byref(RecLen), 1)
if cgrp.m_typ != 0: # This makes sure you only store the groups with beam elements
groups['Grp'].append(cgrp.m_ng)
groups['Max'].append(cgrp.m_max)
groups['Min'].append(cgrp.m_min)
# Always read the length of record before sof_cdb_get is called
RecLen = c_int(sizeof(cgrp))
df_groups = pd.DataFrame.from_dict(groups)
# +============================================================================+ Getting crossection details of nodes
ie = c_int(0)
nodes = {'Node':[], 'Grp':[], 'X':[], 'Y':[], 'Z':[]}
while ie.value < 2:
datalen.value = sizeof(CNODE)
RecLen = c_int(sizeof(cnode))
ie.value = py_sof_cdb_get(Index, 20, 00, byref(cnode), byref(RecLen), 1)
nodes['Node'].append(cnode.m_nr) # node-number
nodes['X'].append(cnode.m_xyz[0]) # x coordinates
nodes['Y'].append(cnode.m_xyz[1]) # y coordinates
nodes['Z'].append(cnode.m_xyz[2]) # z coordinates
nodes['Grp'].append(0)
# Always read the length of record before sof_cdb_get is called
RecLen = c_int(sizeof(cnode))
for i, node in enumerate(nodes['Node']):
for index, row in df_groups.iterrows():
grp = row['Grp']
Min = row['Min']
Max = row['Max']
if Min - 1 <= node <= Max + 1:
nodes['Grp'][i] = grp
break