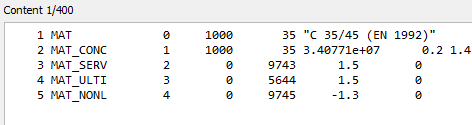
Hello,
I extract Material properties from a Sofistik Database. Looking at the database information, i should be able to read the title with cmat.m_title. But the information is extracted as an array with 17 integers. Which encoding is used to translate these integers into characters?
Check out the example in your installation folder:
C:\Program Files\SOFiSTiK\2020\SOFiSTiK 2020\interfaces\examples\python\python_3.x\number2string\number2string.py
Hello sfr,
thanks for your answer. Unfortunately it is not working as expected for me.
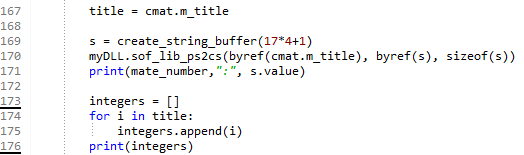
Below is my code to get the Material Name with that string buffer.
^
The output is not showing the correct Titles. For some Material numbers there are no characters at all.
Hey, I still get this weird output, where only one Material title is somewhat useable. For the other materials, I cant get anything reasonable. But the integer array seems to be correct. I dont understand the behavior of the string buffer. Its also not about the cdb. For other cdbs its similar behavior unfortunately. I would be very happy about any ideas what to do
please find attached a small example. Let me know if it did help out.
Try to use the function lng2txt(curLong, nrChar), in some cases you need to use nrChar = 2 and in some nrChar = 4.
Other solution would be to use the function sof_lib_ps2cs(). But I think that lng2txt is simpler to use.
P.S. I have renamed the extension of the PY file to DAT because of the upload policy of the forum. When you download it, just revert it back to .PY. decode_text_from_number_STU.py.dat (5.0 KB)
 ^
^